Tutorial: How to get all the URLs on a website
Learn how to use a crawler to extract all the links from a website. No code required. (⏲️ 2 Minutes)
The simplest way to extract all the URLs on a website is to use a crawler. Crawlers start with a single web page (called a seed), extracts all the links in the HTML, then navigates to those links and repeats the process again until all links have been navigated to.
In this tutorial, we'll show you two ways to setup a crawler to do this — a basic technique that can be done in less than a minute, and an advanced technique that allows you to specify parameters to crawl only specific page types (i.e. product pages) or look for specific keywords and phrases.
Basic Technique: Crawly
Crawly is an online tool that takes a single website and crawls up to 500 total URLs found throughout the site.
Each URL found is classified into one of several page types. The type of a page tells Crawly what kind of content to extract automatically from each page. Once Crawly has fully crawled a website, the result is a beautifully structured data dump of not just the URLs on a website, but also the contents of each URL based on its classified type.
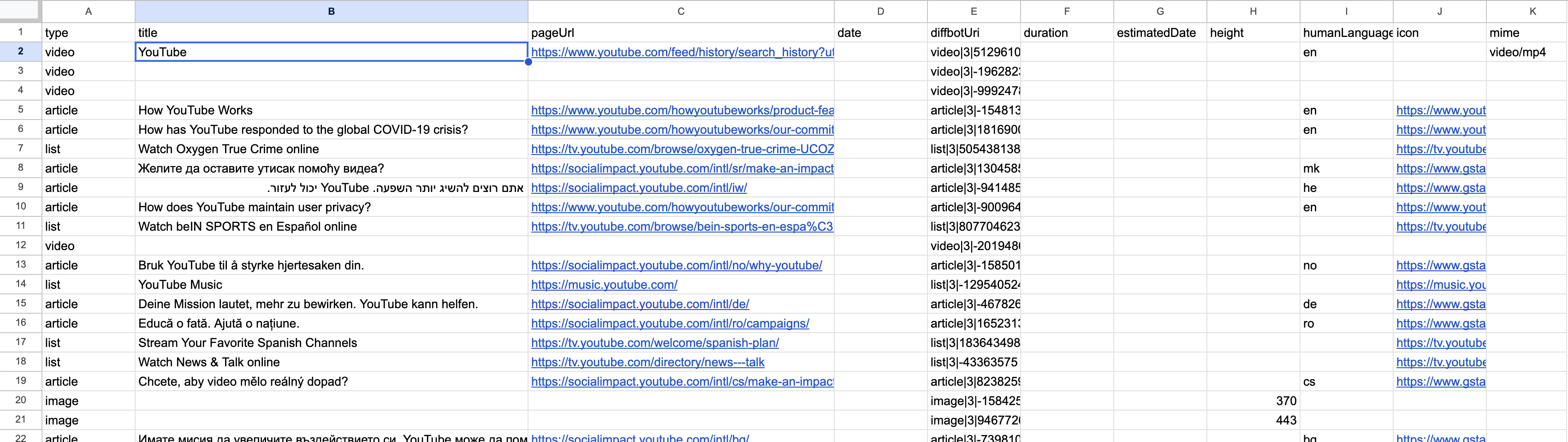
Screenshot of a spreadsheet revealing a sample of URLs extracted from youtube.com
How to use Crawly
- Go to crawly.diffbot.com
- Enter the URL of a website you'd like to extract URLs from
- Enter your email
- Hit "Crawl my Website"
That's it! When the crawl is complete (it won't take long), Crawly will send you an email with a link to download your crawl results in JSON or CSV format.
While Crawly makes crawling easy, it lacks the fine tuned control you might need for deeper crawls.
Advanced Technique: Diffbot Crawl
Diffbot's web data platform includes an enterprise-grade crawler. Diffbot Crawl is not only used by hundreds of companies to extract content from the web, it also spiders all of the public web to find facts to be structured into the Diffbot Knowledge Graph.
Not coincidentally, Diffbot Crawl also powers Crawly behind the scenes.
With Diffbot Crawl, you can crawl every URL on a website and include processing filters to avoid crawling and extracting data you don't need.
To access, you will need a Diffbot Plus plan or higher.
How to use Diffbot Crawl
- Go to app.diffbot.com/crawls/new
- Under Name: Enter a name for your crawl.
- Under Seed URLs: Enter the URL of a website you'd like to extract URLs from
- Scroll to the bottom and enter your email under Email Notification to be notified when the crawl is complete.
This will set you up with a high performance crawl across a single website. For advanced filters and settings, see Crawl and Processing Patterns and Regexes.